
Claude Opus 4.7: כל החידושים, הבנצ’מרקים והשינויים השוברים
Claude Opus 4.7 שוחרר ב-16 באפריל 2026 והוא המודל הזמין המתקדם ביותר של Anthropic. השדרוג הזה מביא קפיצה משמעותית בביצועי

כשהשוק עוד לא הספיק להתאושש מההשקה של Claude Opus 4.7 ו-GPT-5.4, החברה הסינית DeepSeek זרקה לזירה שני מודלים חדשים: DeepSeek V4 בגרסת Pro ובגרסת Flash. שניהם משוחררים כקוד פתוח תחת רישיון MIT, שניהם תומכים בחלון הקשר של מיליון טוקנים, ושניהם מתומחרים במחירים שגורמים לכל מי שעובד עם כלי AI מודלי שפה לעצור ולנשום. אם אתם חיים בעולם הזה, אתם בטח כבר ראיתם את הגלים — אבל הפעם זה לא רק עוד הכרזה של “המודל הכי חכם בעולם”. זה משהו אחר.
DeepSeek השיקה את V4 ב-24 באפריל 2026, ובאותו יום הפכה את המודל לזמין דרך ה-API ושחררה את המשקלים המלאים ב-Hugging Face. שתי הגרסאות בנויות על ארכיטקטורת Mixture-of-Experts (MoE), אבל הן מכוונות למשתמשים שונים לחלוטין. בעיניי, הדבר הראשון שתופס תשומת לב הוא לא רק הביצועים — אלא איך הם הצליחו להגיע אליהם בלי לשרוף תקציב כמו של מדינה קטנה.
עם 1.6 טריליון פרמטרים סך הכל ו-49 מיליארד פעילים לכל טוקן, V4-Pro אומן על 33 טריליון טוקנים ומכוון להתחרות במודלים הסגורים של OpenAI ו-Anthropic. אם זוכרים את סקירת GPT-5.4 שיצא לפני כמה חודשים — V4-Pro מנסה להתחרות בדיוק שם, בקטגוריה של מודלי הדגל. השאיפה ברורה: ביצועים פרונטיר, מחיר של פיתוח קוד פתוח.
V4-Flash הוא המודל ה”קטן”: 284 מיליארד פרמטרים סך הכל, 13 מיליארד פעילים לכל טוקן, אומן על 32 טריליון טוקנים. הוא מיועד לסיטואציות שדורשות מהירות ויכולת לייצר המון טוקנים בלי לפגוע באיכות הליבה. את כל הפרטים הטכניים, גרסאות API והיסטוריית המודלים תמצאו בדף הכלי DeepSeek שבאתר. כן, זה אותו DeepSeek שהפיל את שוק ה-AI בתחילת 2025 — וכן, הם רק התחממו.
זה החלק שהכי מרגש אותי בכל ההכרזה. לרוב השוק רגיל לחשוב ש”גרסת Flash” של מודל היא תרגיל באיכות נחותה לעומת הדגל. כאן המצב שונה לגמרי, ובחלק מהמדדים הפער כל כך זניח שלרוב המקרים פשוט אין סיבה לשלם על Pro. בואו נבדוק את הנתונים בגובה העיניים.
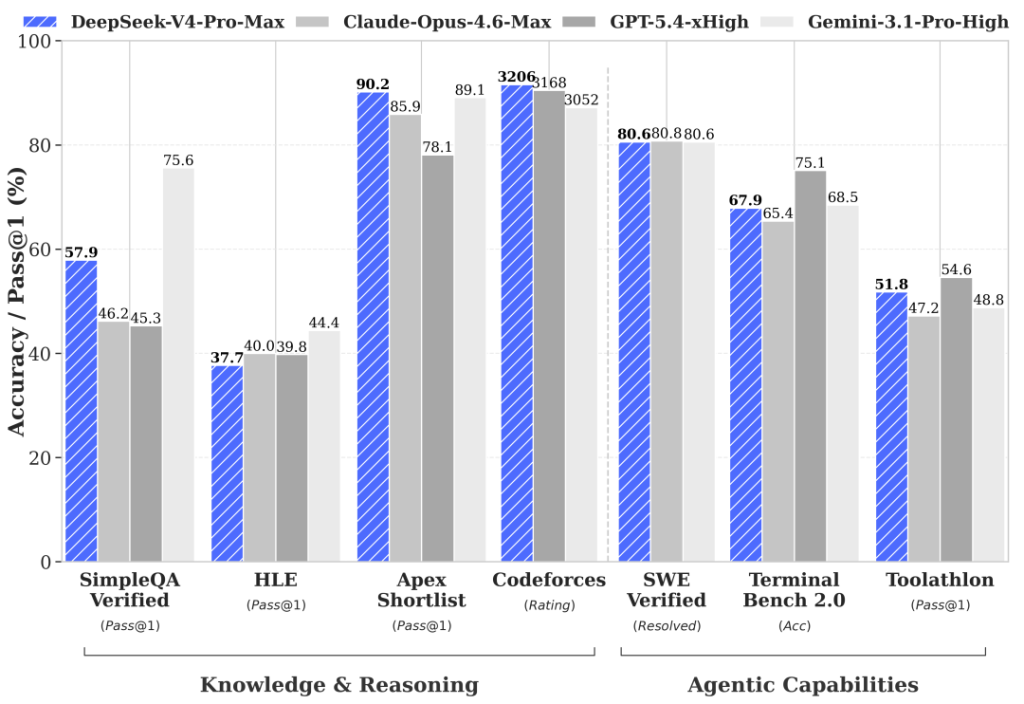
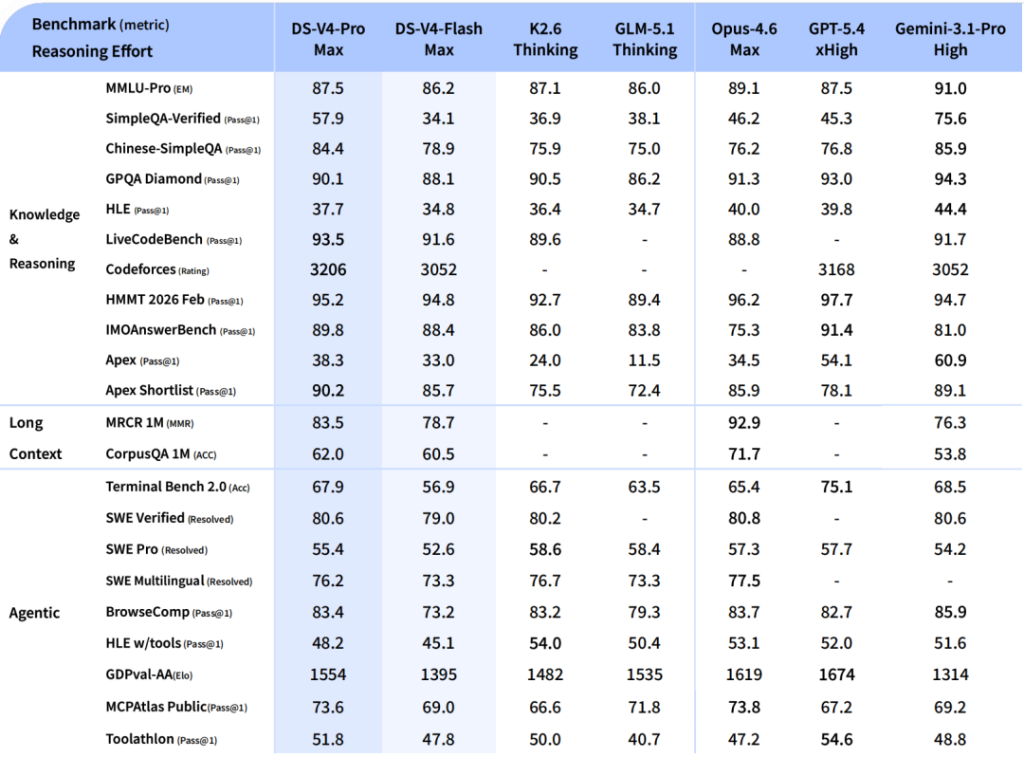
על SWE-bench Verified — הבנצ’מרק החשוב ביותר לקוד agentic — V4-Pro מקבל 80.6% ו-V4-Flash 79.0%. פער של 1.6 נקודות בלבד. על LiveCodeBench, Pro מגיע ל-93.5% ו-Flash ל-91.6%. על Terminal-Bench 2.0 הפער יותר משמעותי: Pro 67.9% מול Flash 56.9%. על Codeforces, V4-Pro מקבל דירוג 3206 — מעל GPT-5.4 שעומד על 3168.
על GPQA Diamond — מבחן ההיגיון של רמת דוקטורט — V4-Pro מקבל 90.1%. על GSM8K (מתמטיקה) הוא מתקרב ל-92.6%. על HMMT 2026 — אולימפיאדת המתמטיקה — V4-Pro מגיע ל-95.2%, פער של נקודה אחת בלבד מ-Claude שעומד על 96.2%. על Humanity’s Last Exam, אחד המבחנים הקשים שיש כיום, V4-Pro מקבל 37.7% — קצת מתחת ל-40% של Claude אבל עדיין באותה ליגה.
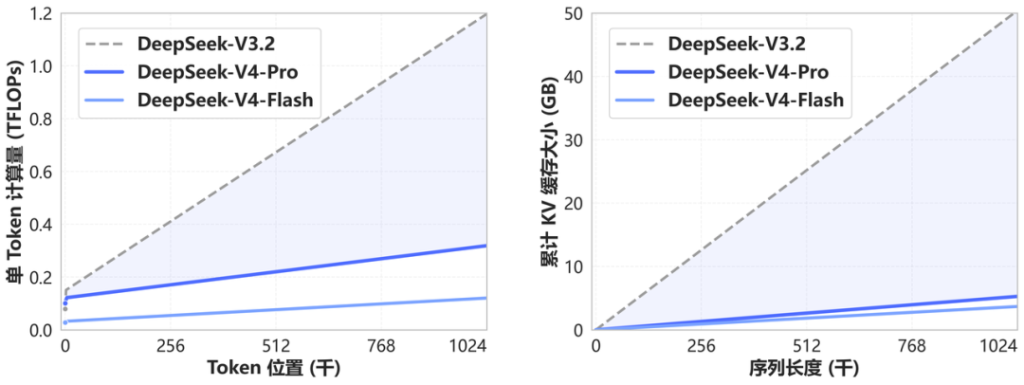
שני המודלים נושאים חלון של 1M טוקנים, וההישג כאן הוא לא רק במספר — אלא ביעילות. בעזרת ארכיטקטורת DSA (DeepSeek Sparse Attention) שמשלבת CSA ו-HCA, V4-Pro דורש רק 27% מה-FLOPs של V3.2 ועוד 10% מגודל ה-KV cache. Flash מצליח לרדת ל-10% FLOPs ו-7% KV cache לעומת קודמו. על MRCR 1M Long Context, V4-Pro מקבל 83.5% — נתון מצוין שמראה שהחלון הענק לא רק שיווקי אלא באמת שמיש.
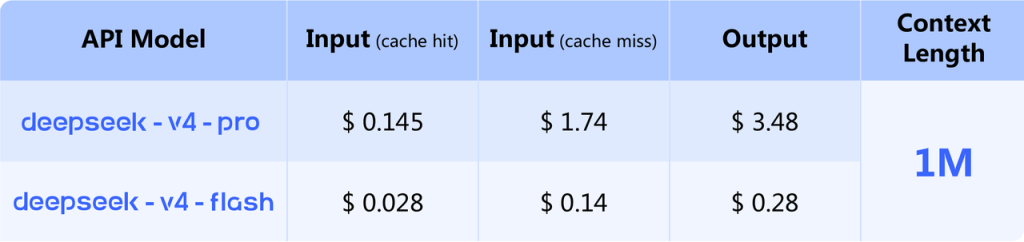
DeepSeek V4-Pro: 1.74$ לאינפוט ו-3.48$ לאאוטפוט לכל מיליון טוקנים. V4-Flash: 0.14$ לאינפוט ו-0.28$ לאאוטפוט. למי שעובד עם cache hits, המחירים יורדים עוד יותר — Flash מגיע ל-2.8 סנט בלבד למיליון טוקני אינפוט במצב cache hit. בהשוואה: Claude Opus 4.6 עומד על 5$ אינפוט ו-25$ אאוטפוט. כלומר V4-Pro זול פי 7 ב-output, ו-Flash זול פי 89 (כן, פי שמונים ותשע) מ-Claude לאותה תזרים. עבור כל מי שמריץ סוכנים אוטומטיים בקנה מידה, זה לא הבדל — זה שינוי שלם של המודל הכלכלי.
הצד השני של המטבע: V4-Pro מקבל רק 57.9% על SimpleQA-Verified, מבחן הזיכרון העובדתי. ל-Gemini 3.1 Pro יש שם 75.6%. כלומר אם אתם מצפים שהמודל יזכור עובדות נישתיות בדייקנות אבסולוטית, זה לא יהיה הבחירה הראשונה. גם על Humanity’s Last Exam הוא מפגר אחרי Claude. דבר נוסף — DeepSeek מציינים בפירוש שזו גרסת Preview, ושיהיו עדכוני post-training. אין כרגע אינטגרציה native ל-AWS Bedrock או ל-Azure OpenAI, ולמודל אין Jinja chat template מובנה — צריך לקודד ידנית. כדאי לקחת את הביצועים הראשוניים עם קורטוב של מלח עד שתהיה גרסת stable.
על מדד Artificial Analysis Intelligence Index, V4-Pro מקבל 52 — מקום שני בקרב מודלי קוד פתוח, מאחורי Kimi K2.5 של Moonshot AI שיורשו (Kimi K2.6) הגיע ל-54. V4-Flash מקבל 47 — בדיוק כמו Claude Sonnet 4.6 במאמץ מקסימלי. כלומר Flash ה”קטן” הזה מתחרה במודל בינוני סגור של Anthropic — במחיר שנמוך פי כמה עשרות. כשמסתכלים על המפה הכללית, DeepSeek חזרו להיות שחקן רציני בליגה הפתוחה.
V4-Pro מתאים לעבודות agentic coding כבדות, מהנדסי תוכנה שעובדים מול codebase גדול, ולכל מי שצריך הספק רציני בלי להיכנס לעלויות של Opus או GPT-5.4. V4-Flash מתאים לסיסטמים שמייצרים הרבה טוקנים — סוכנים אוטומטיים, classifications בקנה מידה, או ארכיטקטורת tiered routing שבה Flash מטפל ב-90% מהבקשות ו-Pro נכנס רק לקריטיות. כאן בישראל, עם תקציבים יותר קטנים מסטארטאפים אמריקאיים, זה לעיתים ההבדל בין PoC שעולה 100 שקל לחודש ל-PoC שעולה 1000.
ב-DeepSeek שילבו עוד כמה חידושים שראויים לציון, גם אם הם פחות זוהרים מהכותרות הראשיות. אלה הפרטים הקטנים שלרוב מבדילים בין מודל “בסדר” למודל שבאמת אפשר לבנות עליו תשתית פרודקשן רצינית. כדאי להכיר אותם לפני שמחליטים לבחור — או לדחות.
שני המודלים משתמשים ב-Manifold-Constrained Hyper-Connections (mHC) — טכניקה שמרסנת את ה-residual connections באמצעות אלגוריתם Sinkhorn-Knopp ומייצבת אימון בסקאלות ענקיות. בנוסף, DeepSeek ויתרו על AdamW לטובת ה-Muon Optimizer, מה שתרם להתכנסות יציבה יותר במהלך האימון. שניים אלה אולי נשמעים כפרטים אקדמיים, אבל בפועל הם הסיבה שהמודלים האלה הצליחו להתאמן עם תקציב חישובי הרבה יותר נמוך מהמתחרים הסגורים — וזה משתקף ישירות במחיר הסופי לצרכן.
שני המודלים תומכים גם במצב “חשיבה” וגם במצב רגיל ללא חשיבה, וניתן להחליף ביניהם דרך ה-API לפי הצורך. עבור משימות agentic מורכבות זה משמעותי — אתם יכולים להפעיל reasoning עמוק כשצריך ולחסוך טוקנים כשלא. יש גם אינטגרציה native ל-Claude Code ול-OpenCode, מה שאומר שאם אתם כבר עובדים עם הסביבות האלה, המעבר ל-V4 הוא כמעט שקוף.
שלוש השאלות שחזרו הכי הרבה בקהילה הישראלית מאז ההכרזה. אם יש לכם שאלה שלא מופיעה כאן — כתבו לי בתגובות ואענה אישית. בואו נסגור את הפינות החשובות לפני שמקבלים החלטה.
כן. המודל אומן על נתונים רב-לשוניים ותומך בכל השפות הגדולות, כולל עברית. עם זאת, DeepSeek לא פרסמו בנצ’מרקים ספציפיים לעברית, ולפי תחושת השטח של חלק מהמשתמשים בקהילה הישראלית, האיכות בעברית טובה אך עדיין לא בליגה של Claude או GPT-5.4 בעבודות יצירתיות מורכבות.
תיאורטית כן, כי המשקלים פתוחים ברישיון MIT. בפועל V4-Pro דורש קלאסטר GPU רציני; V4-Flash בר-הרצה על תשתיות אנטרפרייז עם תכנון נכון. גרסאות quantized צפויות מקהילת הקוד הפתוח בקרוב, ואז גם משתמשי בית עם GPU חזק יוכלו לנסות.
על פי ההכרזה הרשמית של DeepSeek, המודלים הישנים יוסרו מה-API ב-24 ביולי 2026. אם יש לכם פרודקשן שרץ על המודלים הישנים, כדאי להתחיל לתכנן את המעבר ל-V4 כבר עכשיו ולא ביום האחרון.
DeepSeek V4 הוא לא רק “עוד שחרור”. זה מודל פתוח עם ביצועים שמתקרבים לדגלים הסגורים, חלון הקשר של מיליון טוקנים, ומחיר שמכריח את כל השוק לחשוב מחדש על תמחור. ב-Flash בפרט יש פוטנציאל אמיתי לשנות איך אנחנו בונים מערכות בקנה מידה. אם הייתם מהססים עד עכשיו לבחון מודלים פתוחים בפרודקשן — זה הרגע לתת לזה הזדמנות אמיתית. תתחילו עם Flash, תבנו tiered routing, ותראו מה זה עושה לשורת ה-COGS שלכם. אני בכל מקרה מתכוון לבחון את שניהם בפרויקטים הקרובים — ואשתף תוצאות.
Claude Opus 4.7 שוחרר ב-16 באפריל 2026 והוא המודל הזמין המתקדם ביותר של Anthropic. השדרוג הזה מביא קפיצה משמעותית בביצועי

שני מודלים מטורפים, GPT Codex 5.3 ו-Claude Opus 4.6, יצאו בבת אחת! גלו מי המנצח הגדול בקרב על עתיד

חברת OpenAI משיקה את GPT-5.4 – מודל דגל המציג יכולות שליטה עצמאית במחשב, כתיבת קוד מתקדמת וביצוע משימות משרדיות מורכבות.